Paddle Lite特性全解读 多硬件支持与轻量化部署引领移动端AI未来
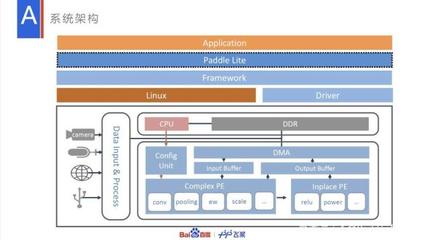
在人工智能技术飞速发展的今天,模型的端侧部署已成为行业关键挑战。百度飞桨推出的Paddle Lite,作为一款高性能、轻量级的深度学习推理框架,正以其卓越的多硬件支持能力和极致的轻量化部署方案,为移动端、嵌入式及边缘计算场景注入强大动力,成为开发者手中不可或缺的利器。
一、 核心亮点:广泛而深入的多硬件支持
Paddle Lite最引人瞩目的特性之一,是其对异构计算环境的卓越兼容性。它不仅全面支持ARM CPU(如Cortex-A系列)、GPU(Mali/Adreno)、NPU(华为昇腾、联发科APU等)以及FPGA、DSP等多种硬件平台,更通过统一的API接口和高度优化的内核,实现了“一次开发,多处部署”。这种设计极大地降低了开发者在不同硬件间迁移和调优的成本,使得从手机、平板到物联网设备、自动驾驶车载平台,都能高效运行AI模型,真正打破了硬件壁垒。
二、 技术基石:极致的轻量化与高性能
面对端侧设备严苛的存储、算力和功耗限制,Paddle Lite在轻量化与性能优化上做到了行业领先。
- 模型优化工具链:内置的模型优化工具(如OPT工具)能对训练好的模型进行剪枝、量化、融合等操作,在几乎不损失精度的情况下,显著压缩模型体积、提升推理速度。例如,INT8量化可将模型尺寸减小至原来的1/4,同时大幅提升计算效率。
- 高效内核与调度:框架采用了深度优化的算子内核,并具备智能的算子融合与图优化能力。其创新的异构调度器能动态分析模型结构与硬件特性,实现计算任务在CPU、GPU等处理器间的自动、高效分配,充分挖掘硬件潜能。
- 内存与功耗优化:通过精细的内存复用策略和低功耗指令集优化,Paddle Lite在保证速度的有效控制了内存占用与设备能耗,这对于电池供电的移动设备至关重要。
三、 开发者体验:便捷的部署与完善的生态
Paddle Lite致力于提供流畅的开发体验。它支持PaddlePaddle、ONNX、TensorFlow等多框架模型格式的导入,简化了模型转换流程。清晰的C++、Java、Python API设计,以及丰富的预训练模型库和详尽的文档教程,让开发者能够快速上手。其与飞桨全栈AI平台的深度集成,意味着开发者可以享受从模型训练、优化到端侧部署的一站式服务,显著提升AI产品的落地效率。
四、 应用场景展望
凭借上述特性,Paddle Lite已在智能手机摄影增强、实时翻译、工业质检、无人零售、智能安防等众多领域得到广泛应用。随着5G和物联网的普及,对端侧智能的需求将呈现爆炸式增长。Paddle Lite持续演进的多硬件支持与轻量化技术,无疑将为AI在更广阔边缘场景的普及奠定坚实基础,推动人工智能从“云端”走向“身边”。
总而言之,Paddle Lite以其强大的多硬件适配能力、顶尖的轻量化性能以及友好的开发体验,成功解决了AI模型端侧部署的核心痛点。它不仅是一个工具,更是连接AI算法与万千物理设备的关键桥梁,正在持续推动着智能世界的边界拓展。
如若转载,请注明出处:http://www.didihaohuo.com/product/52.html
更新时间:2026-06-19 17:45:58